chapter06 基本图形
文章目录
基本图形
1、条形图
安装包install.packages("vcd")
安装包包含测试数据Arthritis,以及用户荆棘图组件spinogram
(1)简单的条形图
|
|
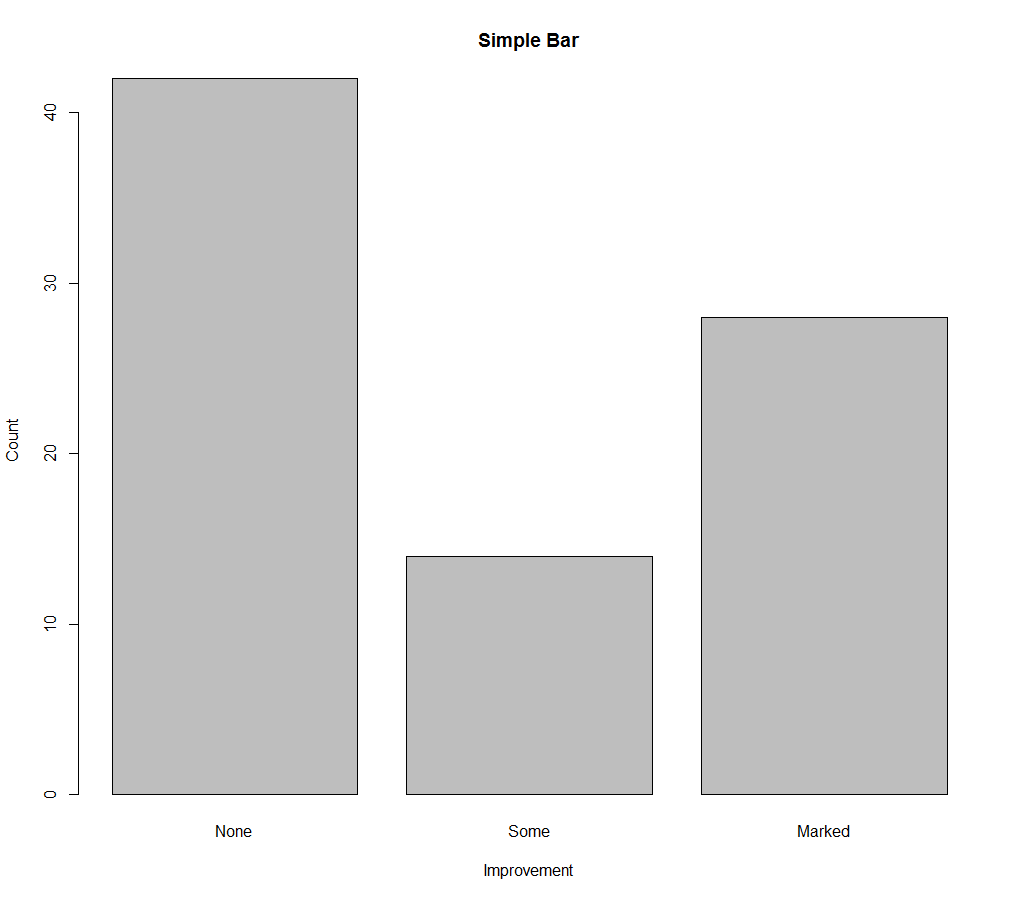
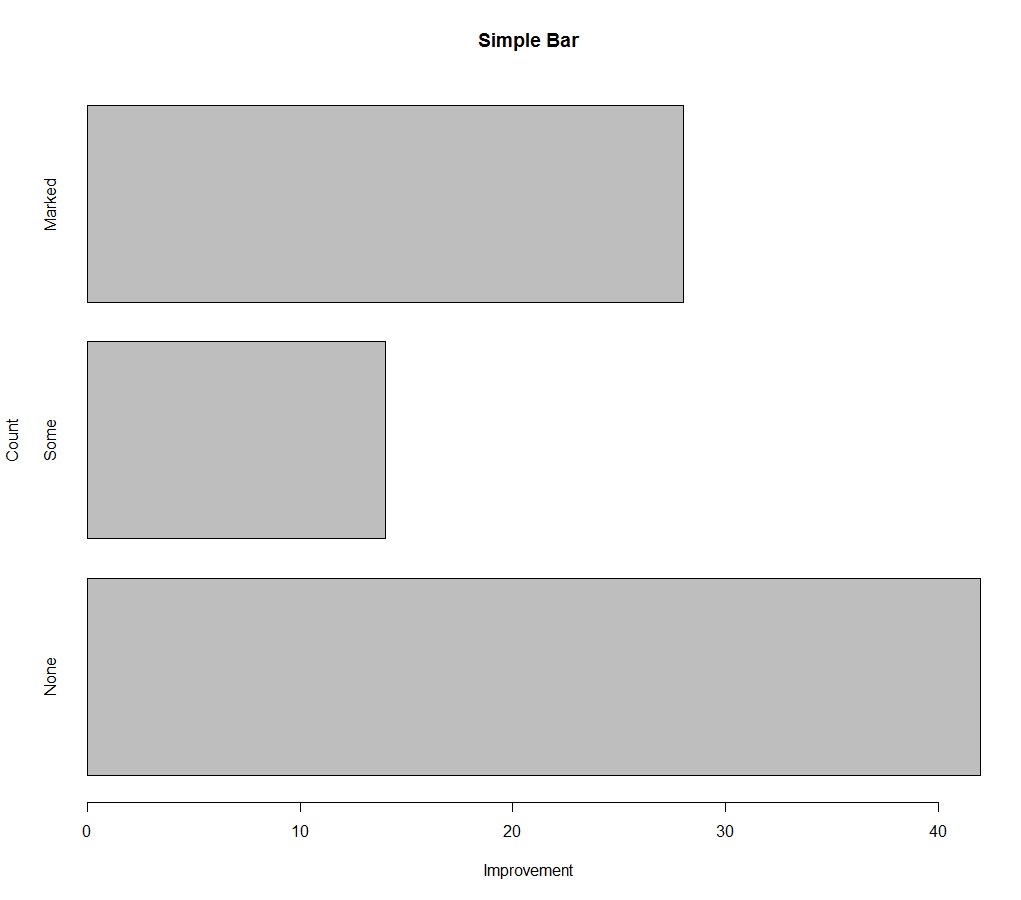
如果要绘制的类别型变量是一个因子或有序型因子,就可以使用函数plot()快速创建一幅垂直条形图。
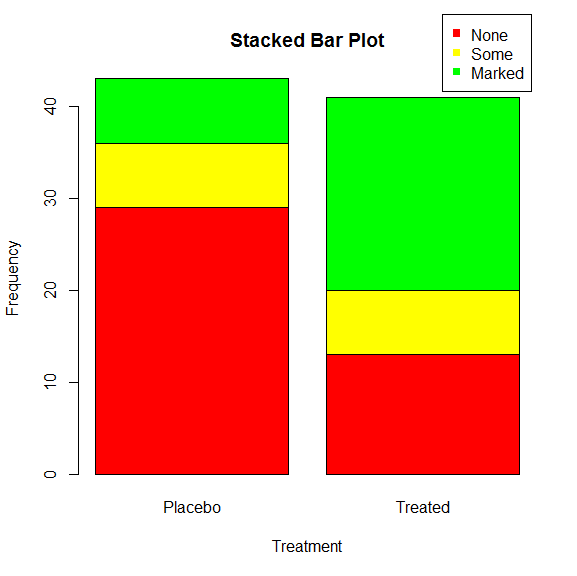
(2)堆砌条形图和分组条形图
|
|

(3)均值条形图
|
|
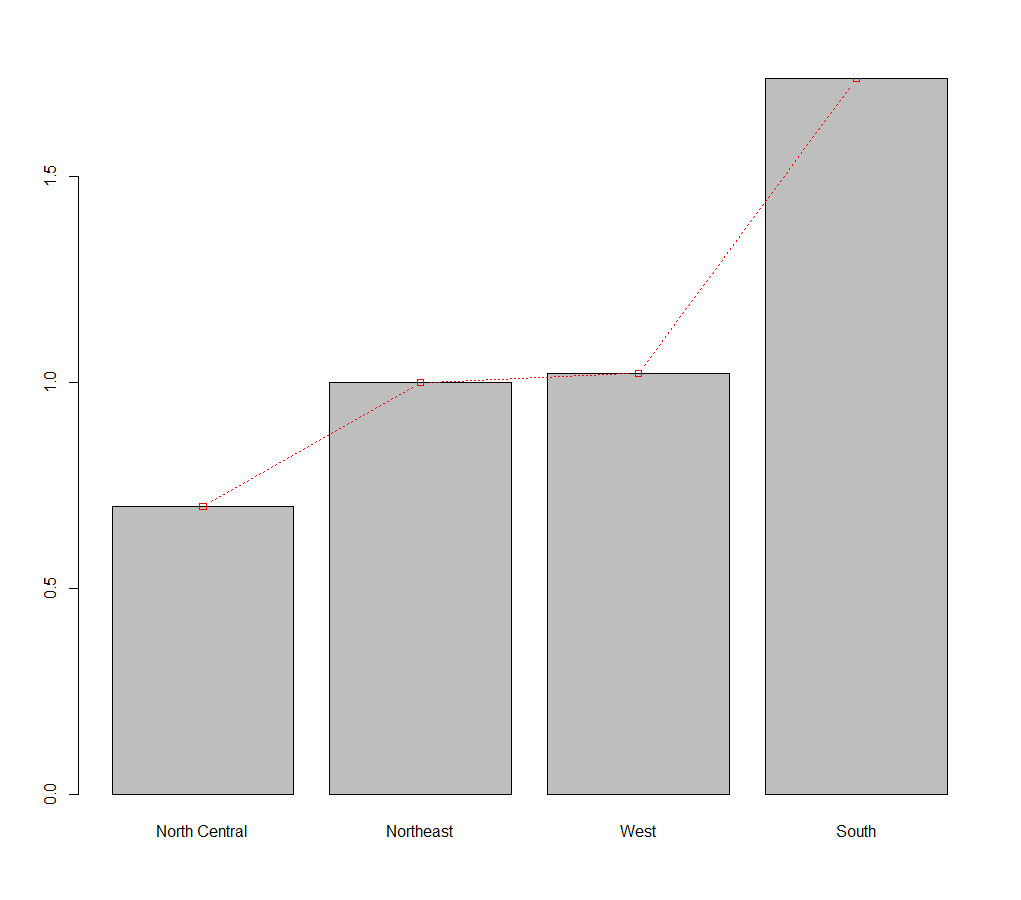
(4)微调柱状图
|
|
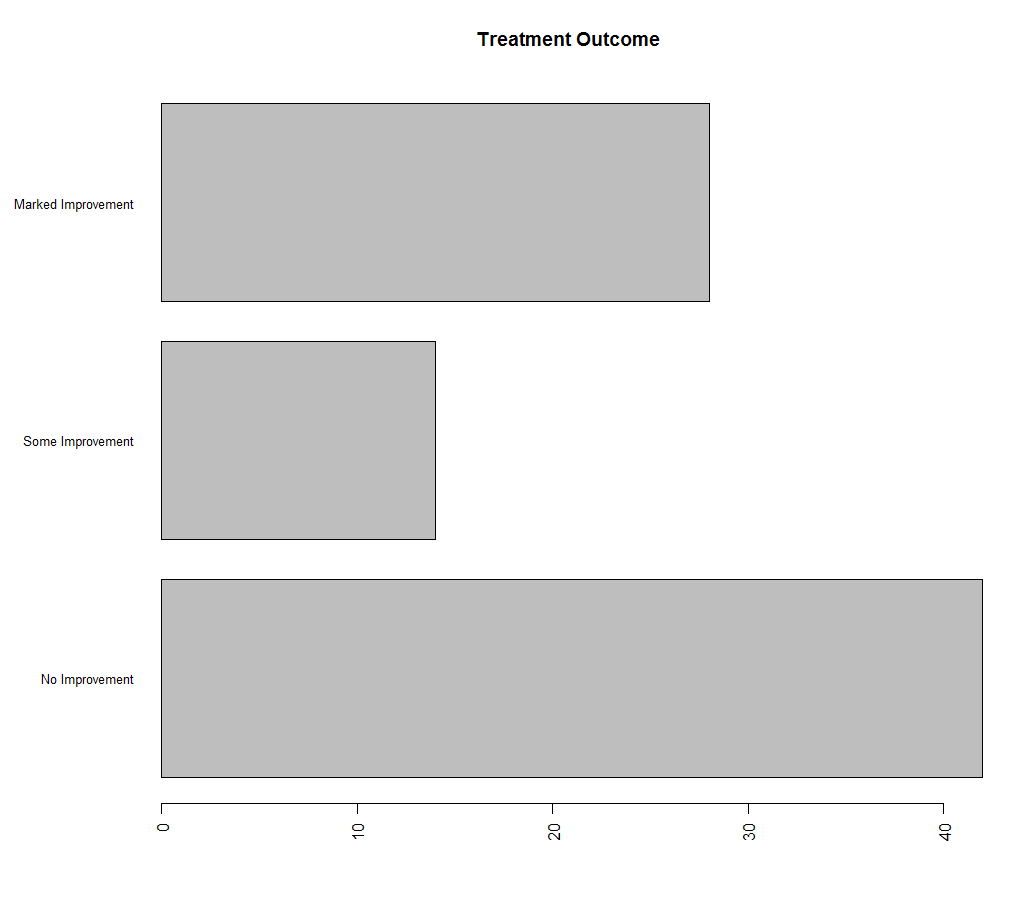
(5)棘状图
棘状图对堆砌条形图进行了重缩放,这样每个条形的高度均为1,每一段的高度即表示比例。棘状图可由vcd包中的函数spine()绘制
|
|
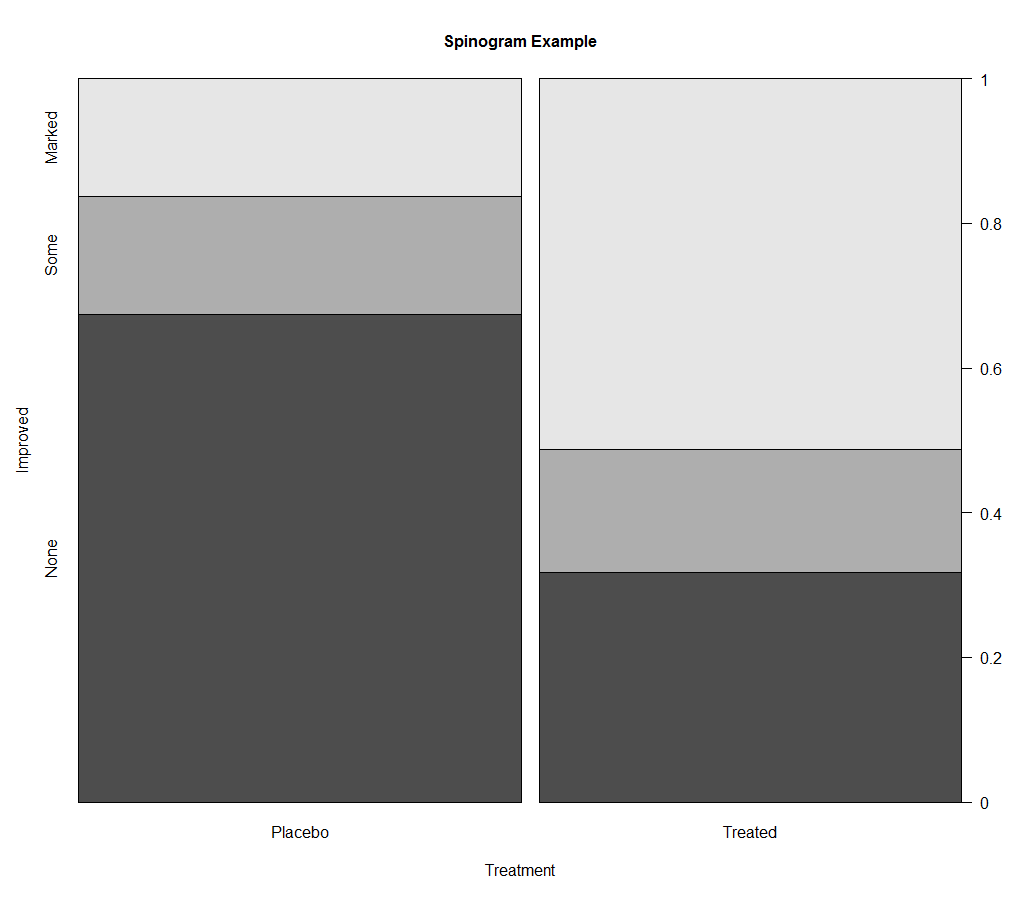
2、饼图
(1)饼图(表达信息能力弱,不推荐)
|
|
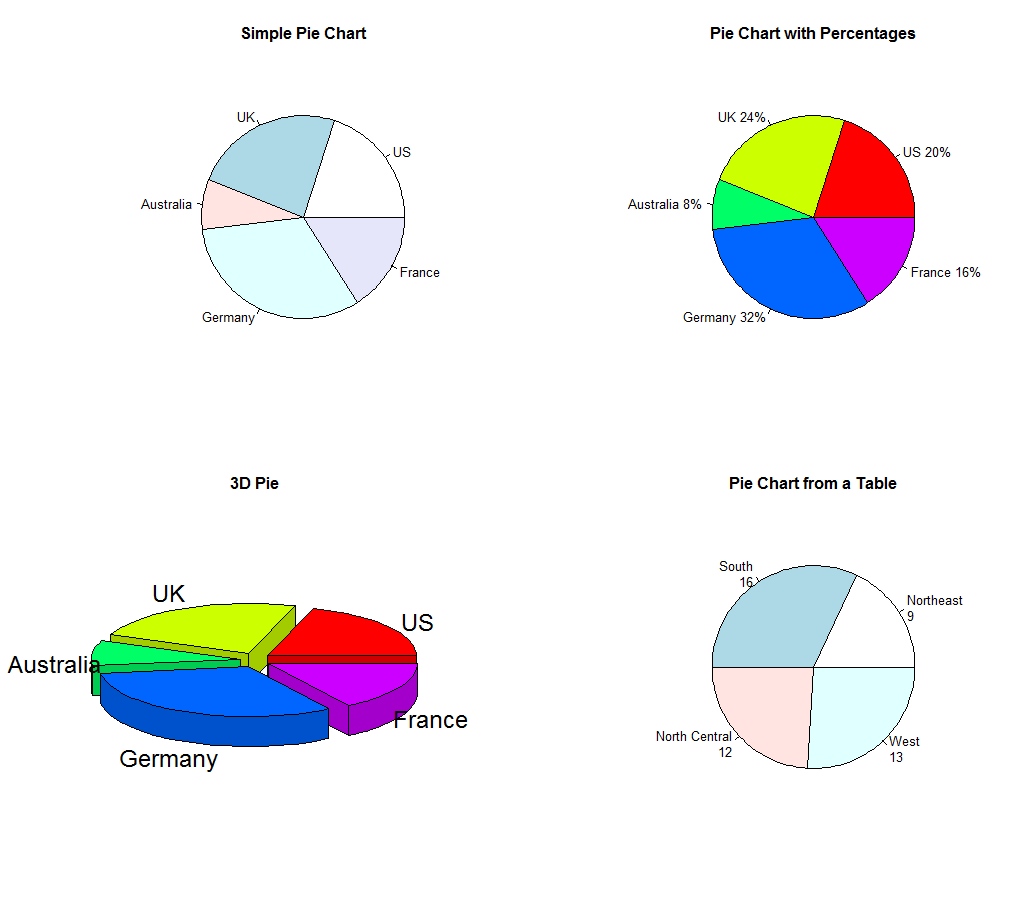
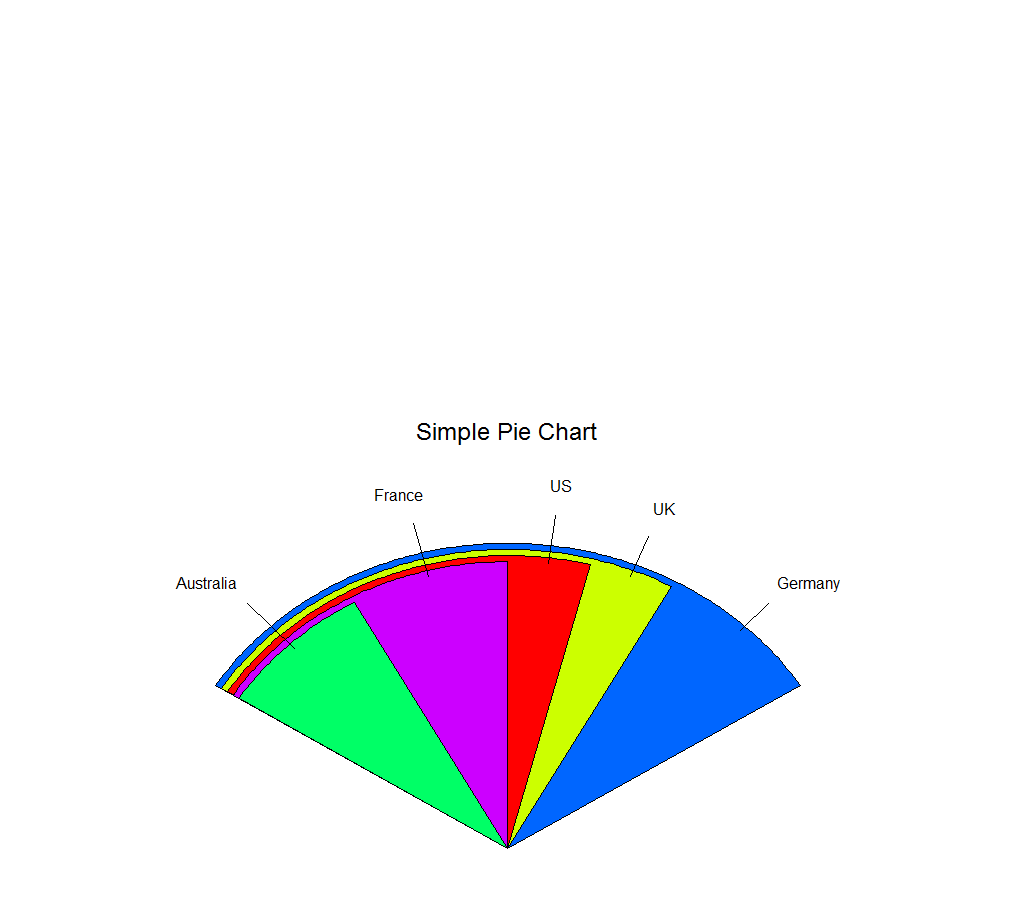
(2)折叠扇图
|
|
3、直方图
|
|

4、核密度图
估计随机变量的概率密度函数。
|
|
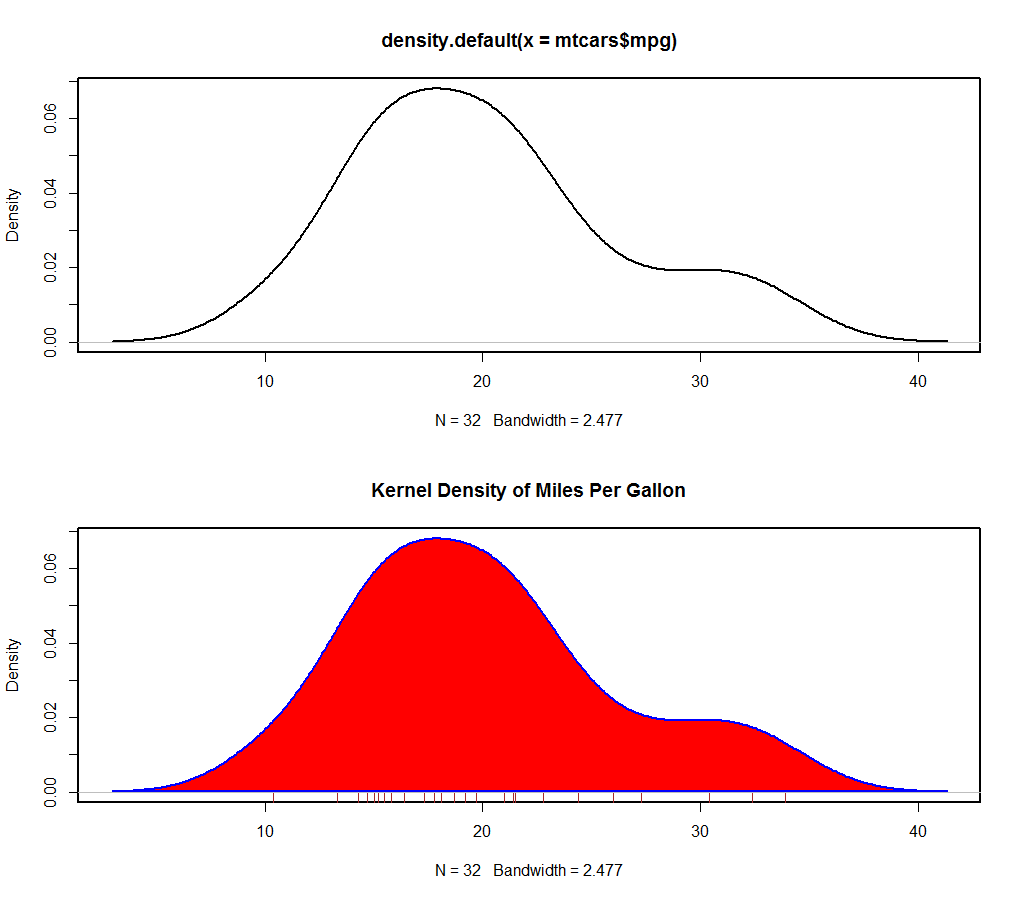
|
|

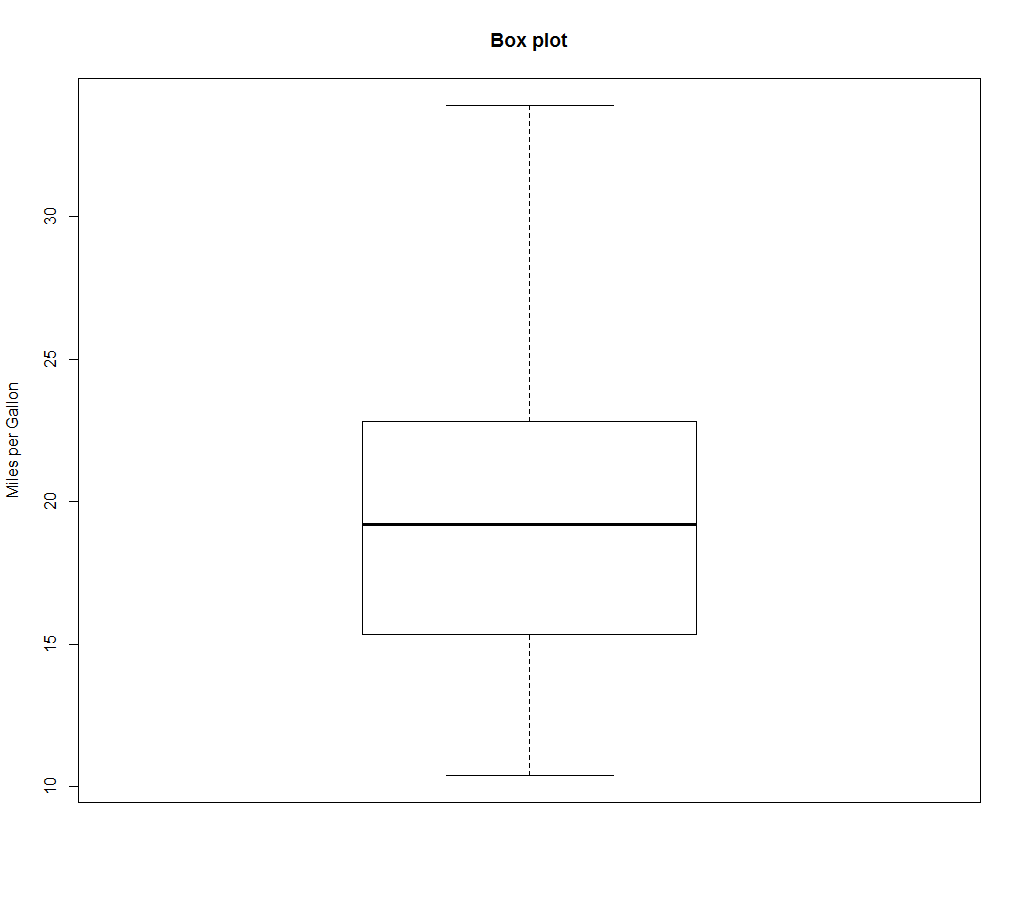
5、箱线图
箱线图(又称盒须图)通过绘制连续型变量的五数总括,即最小值、下四分位数(第25百分位数) 、中位数(第50百分位数)、上四分位数(第75百分位数)以及最大值,描述了连续型变量的分布。formula 参数例如:y ~ A*B则将为类别型变量A和B所有水平的两两组合生成数值型变量y的箱线图。
boxplot(formula, data=dataframe)
|
|
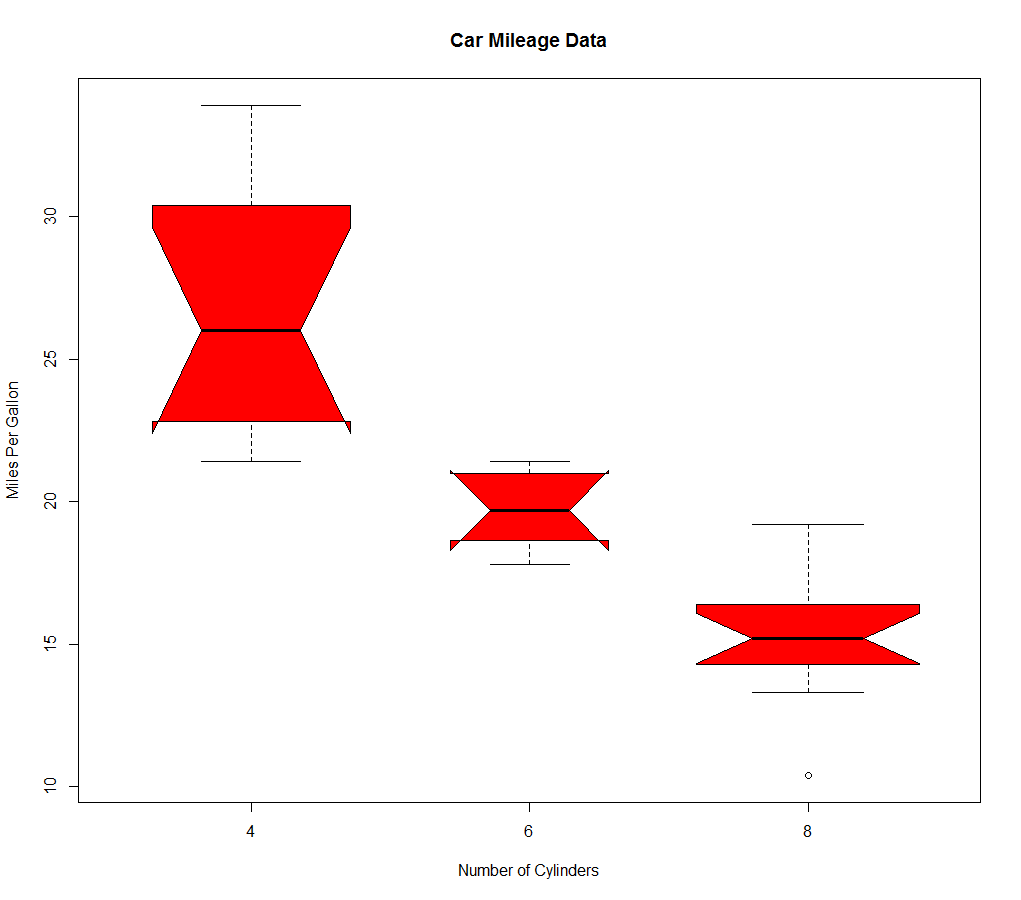
(1)并列箱线图跨组比较
|
|

|
|
|
|
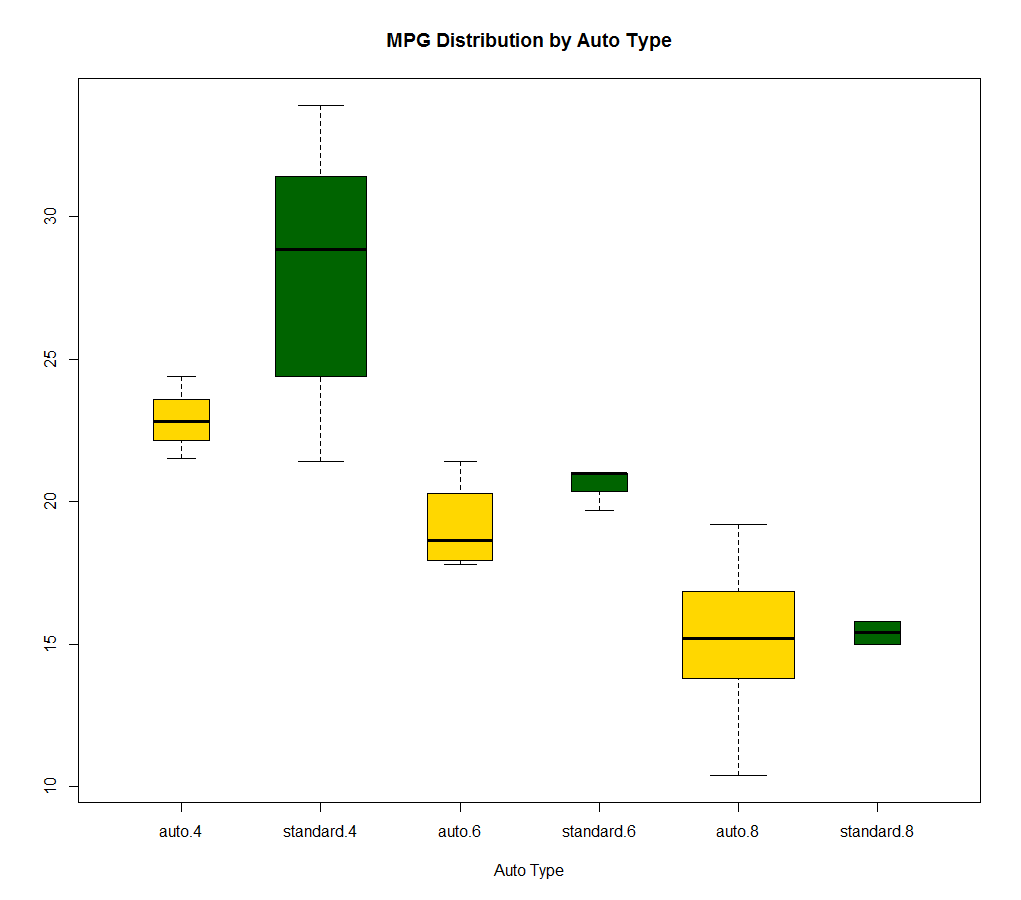
(2)小提琴图
Vioplot(x1,x2,…,names=,col=)
|
|
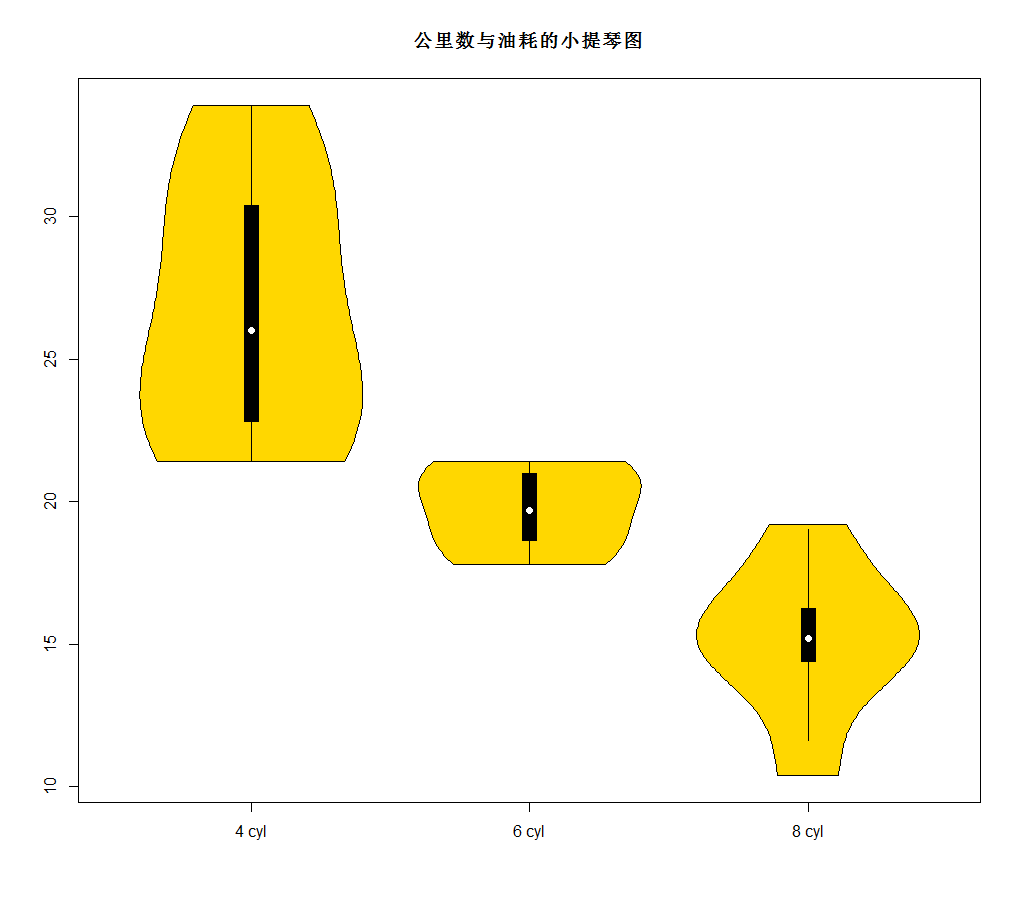
- 在图中,白点是中位数,黑色盒型的范围是下四分位点到上四分位点,细黑线表示须。外部形状即为核密度估计。
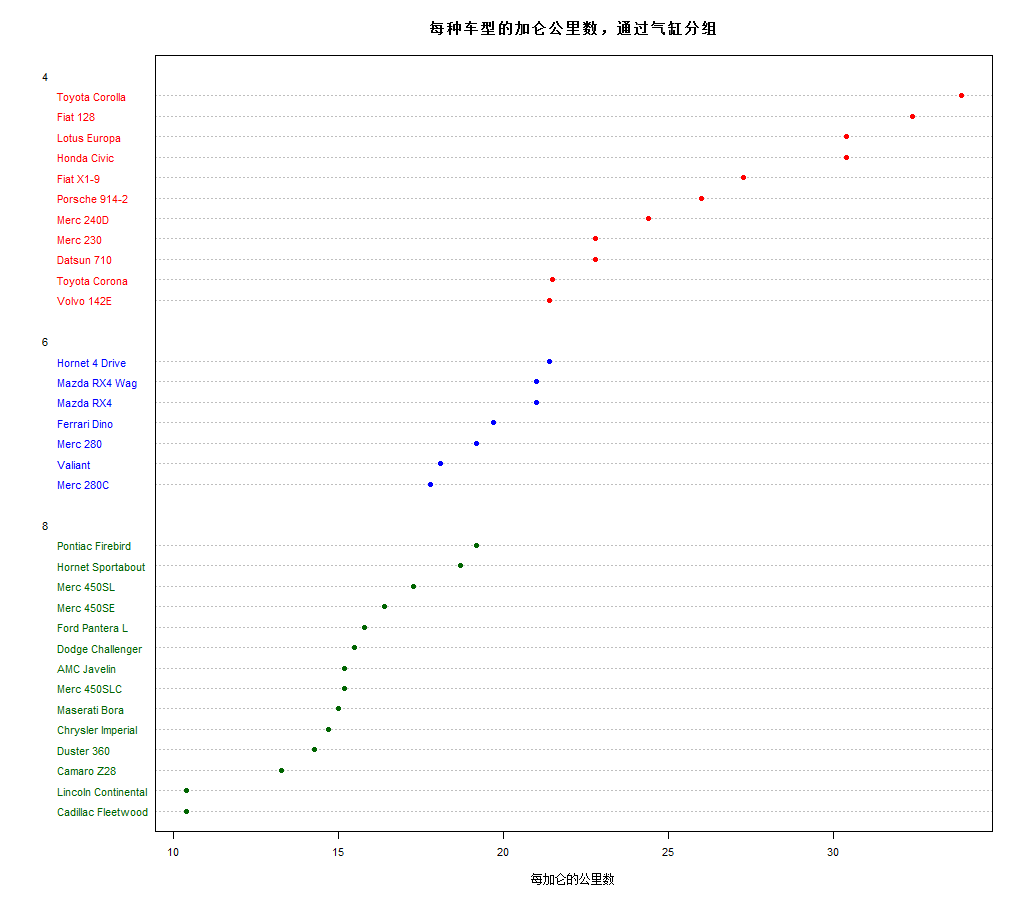
6、点图
dotchart(x,labels=)
|
|
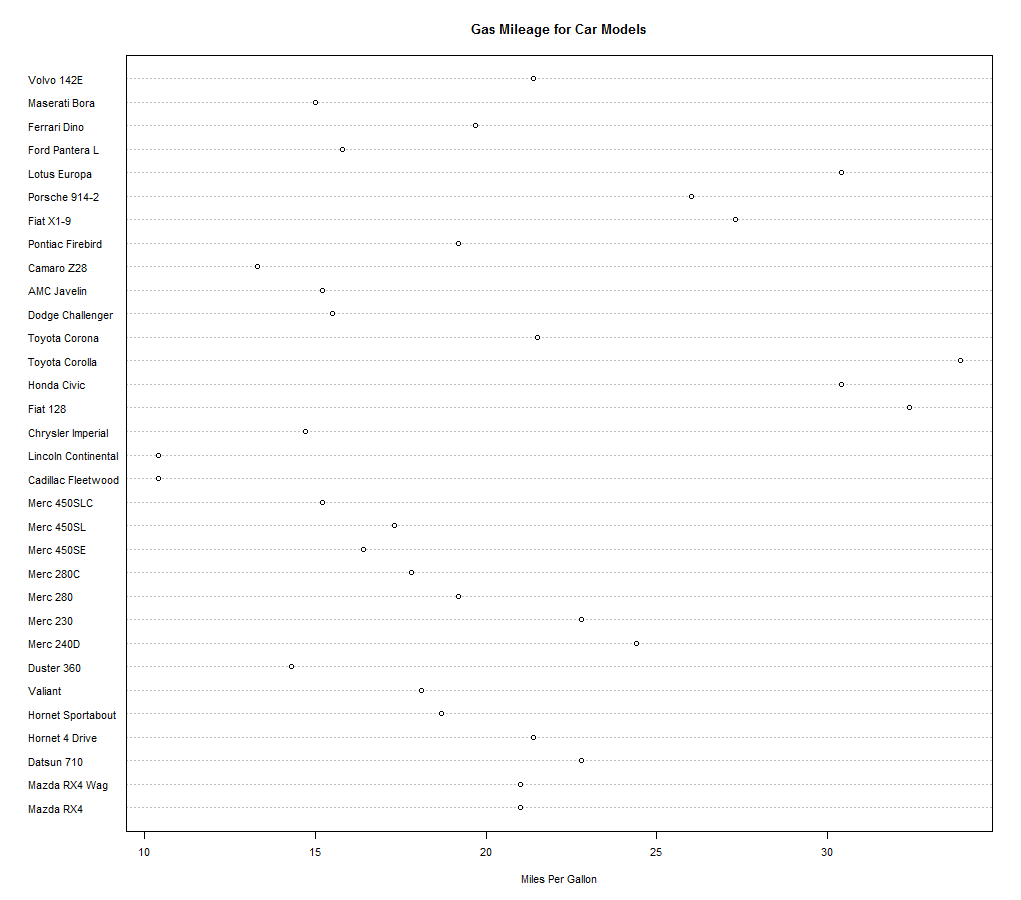
|
|