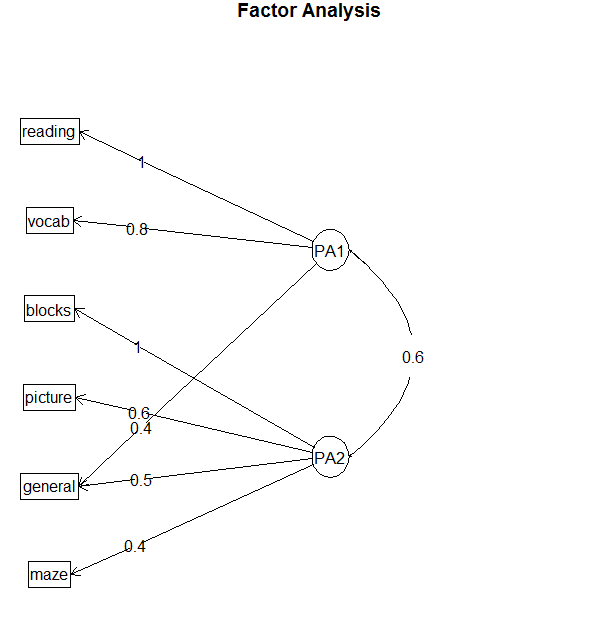
>
> fa.varimax <- fa(correlations, nfactors=2, rotate="varimax", fm="pa")
> fa.varimax
Factor Analysis using method = pa
Call: fa(r = correlations, nfactors = 2, rotate = "varimax", fm = "pa")
Standardized loadings (pattern matrix) based upon correlation matrix
PA1 PA2 h2 u2 com
general 0.49 0.57 0.57 0.432 2.0
picture 0.16 0.59 0.38 0.623 1.1
blocks 0.18 0.89 0.83 0.166 1.1
maze 0.13 0.43 0.20 0.798 1.2
reading 0.93 0.20 0.91 0.089 1.1
vocab 0.80 0.23 0.69 0.313 1.2
PA1 PA2
SS loadings 1.83 1.75
Proportion Var 0.30 0.29
Cumulative Var 0.30 0.60
Proportion Explained 0.51 0.49
Cumulative Proportion 0.51 1.00
Mean item complexity = 1.3
Test of the hypothesis that 2 factors are sufficient.
The degrees of freedom for the null model are 15 and the objective function was 2.5
The degrees of freedom for the model are 4 and the objective function was 0.07
The root mean square of the residuals (RMSR) is 0.03
The df corrected root mean square of the residuals is 0.06
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
PA1 PA2
Correlation of (regression) scores with factors 0.96 0.92
Multiple R square of scores with factors 0.91 0.85
Minimum correlation of possible factor scores 0.82 0.71
>
>
>
>
>
>
>
>
> library(GPArotation)
> fa.promax <- fa(correlations, nfactors=2, rotate="promax", fm="pa")
Warning message:
In fac(r = r, nfactors = nfactors, n.obs = n.obs, rotate = rotate, :
A loading greater than abs(1) was detected. Examine the loadings carefully.
>
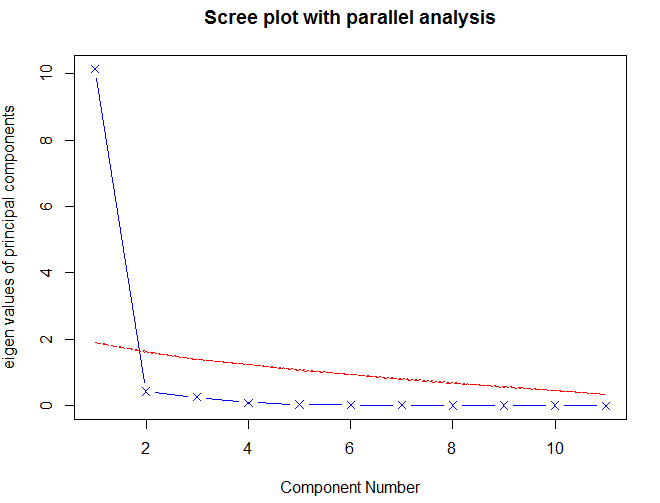
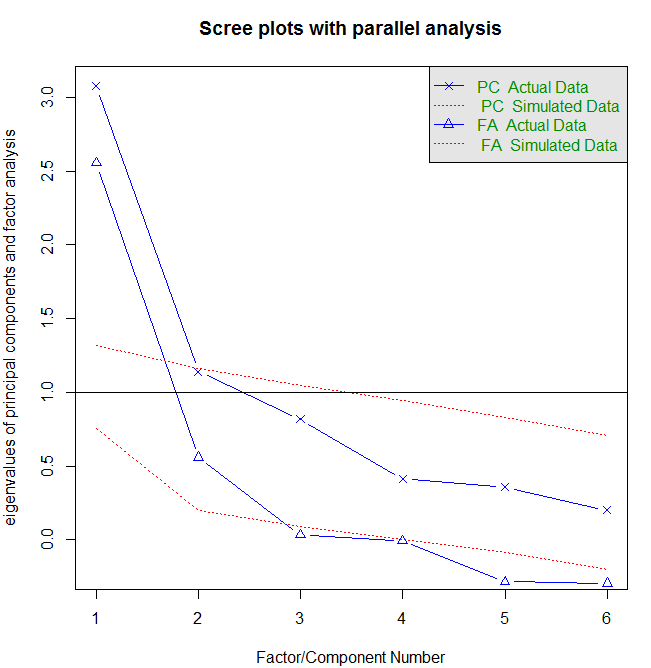
> factor.plot(fa.promax, labels=rownames(fa.promax$loadings))


 123> #若使simple = TRUE,那么将仅显示每个因子下最大的载荷,以及因子> #间的相关系数。这类图形在有多个因子时十分实用。> fa.diagram(fa.promax, simple = FALSE)
123> #若使simple = TRUE,那么将仅显示每个因子下最大的载荷,以及因子> #间的相关系数。这类图形在有多个因子时十分实用。> fa.diagram(fa.promax, simple = FALSE)